Ende 2024 begann eine unscheinbare Datei, durch die Developer-Community zu wandern. Kleine Markdown-Datei, Projektroot, Name: AGENTS.md. Die Idee dahinter: Schreib deinem KI-Coding-Agent auf, was er über dein Projekt wissen muss. Build-Befehle. Coding Conventions. Was er auf keinen Fall anfassen soll.
Am 9. Dezember 2025 übergab OpenAI den Standard an die Agentic AI Foundation (AAIF) unter der Linux Foundation, gemeinsam mit Anthropic, Google, Block und einer wachsenden Zahl von Tool-Herstellern. 60.000+ Open-Source-Repos nutzen AGENTS.md inzwischen. Cursor, Copilot, Gemini, RooCode, alle lesen sie.
Das ist kein Hype. Das ist eine echte Reaktion auf ein echtes Problem.
Aber es ist zu kurz gedacht.
Das Problem, das AGENTS.md löst, und das, das es nicht löst
AGENTS.md ist die Antwort auf Fragmentierung. Jedes Tool hatte seine eigene Konfigurationsdatei erfunden: .cursorrules, CLAUDE.md, GEMINI.md, copilot-instructions.md. Für Multi-Tool-Workflows ein Albtraum, dasselbe vier Mal pflegen, in vier verschiedenen Formaten.
AGENTS.md löst das. Eine Datei, alle Tools. Das ist gut.
Was AGENTS.md aber strukturell nicht lösen kann: Es ist eine Datei. Flat. 150 Zeilen, best practice empfohlen. Sie beschreibt, wie man im Repo arbeitet. Nicht, was das Projekt ist.
Das klingt nach einer feinen Unterscheidung. Es ist keine.
Eine ETH-Zürich-Studie vom März 2026 hat das empirisch untersucht: KI-generierte AGENTS.md-Dateien senkten die Task-Success-Rate um 3 Prozent und erhöhten die Inference-Kosten um über 20 Prozent. Der Grund: Agenten befolgten die Instruktionen zu wörtlich, führten redundante Checks durch, lasen Dateien mehrfach. Schlechte Instruktionen sind deutlich teurer als keine.
Und gut gepflegte AGENTS.md-Dateien, jemand muss sie schreiben. Aktuell halten. Widersprüche bereinigen. Das passiert in der Praxis nicht konsequent, ist aber essenziell wichtig.
Die Community selbst diskutiert inzwischen einen .agent/-Verzeichnis-Ansatz (GitHub Issue #71 im agentsmd-Repo), weil eine einzelne Markdown-Datei für komplexe Projekte strukturell nicht ausreicht. Anforderungen, Architekturdiagramme, API-Contracts, lebende Wikis, das passt nicht in 150 Zeilen.
Hier ist meine These: Das richtige Level of Abstraction ist nicht die Datei. Es ist das Repo.
Was ein OS Repo ist
Ein OS Repo ist kein Monorepo mit Code-Packages. Es ist auch kein erweitertes AGENTS.md. Es ist etwas grundsätzlich Anderes: ein Repo, das ein Projekt vollständig definiert, bevor Entwicklung beginnt.
“OS” steht für Operating System, nicht im technischen Sinne von Linux oder macOS, sondern konzeptuell: Es ist die Schicht, auf der alles andere läuft. Das Betriebssystem eines Projekts.
Die Kernidee:
Erst definieren, dann entwickeln. Alles in Git, teils in natürlicher Sprache und teils maschinenlesbar.
Was “alles” bedeutet:
project-os/
├── brand/ ← Design System, Farben, Typografie, Ton, Ästhetik
├── architecture/ ← Systemdesign, Tech-Stack-Entscheidungen, ADRs
├── workflows/ ← Prozesse, Release-Zyklen, Deployment-Abläufe
├── roles/ ← Wer macht was, Mensch oder Agent
├── data/ ← Maschinenlesbare Projektdaten (JSON, YAML)
├── tools/ ← CLI-Tools, Skripte, Automatisierungen
└── prompts/ ← Wiederverwendbare Agent-InstruktionenDas ist keine Dokumentation, die nach der Entwicklung entsteht. Es ist die Dokumentation, die vor der Entwicklung entsteht und aus der heraus Entwicklung passiert.
Der entscheidende Unterschied: Kontext vs. Definition
AGENTS.md gibt einem Agenten Kontext über einen bestehenden Codebase. Das OS Repo definiert das Projekt, bevor es existiert.
Das klingt philosophisch. Es hat sehr praktische Konsequenzen.
Wenn ein Agent auf ein Projekt trifft, das ein OS Repo hat, kann er folgende Fragen beantworten, ohne nachzufragen:
- Welche Farben verwendet das Design System? (
brand/design-system.md) - Warum wurde Technologie X statt Y gewählt? (
architecture/adr-001.md) - Wie läuft ein Release ab, Schritt für Schritt? (
workflows/release.md) - Was ist der Ton der Kommunikation? (
brand/tone-of-voice.md) - Welche Daten-Schemas existieren? (
data/schema.json) - Welche projektinternen CLI-Befehle gibt es? (
tools/)
Er fragt nicht, weil er alles weiß. Er halluziniert nicht, weil er alles nachschlagen kann. Er macht keine inkonsistenten Entscheidungen, weil die Entscheidungen bereits getroffen wurden, und zwar bewusst, vor Projektstart, von Menschen.
Das ist der Kern: Das OS Repo ist der bewusste Akt, ein Projekt vollständig zu denken, bevor man es baut.
Das Design System als Beispiel
Nehmen wir einen konkreten Fall: Ein neues Webprojekt.
Ohne OS Repo beginnt Entwicklung typischerweise so: Figma-Datei irgendwo, Tailwind-Config mit hardcodierten Farben, Komponenten die nach und nach entstehen, CSS das wächst bis es niemand mehr überblickt. Jeder Entwickler und jeder Agent hat leicht unterschiedliche Vorstellungen davon, was zum Projekt passt.
Mit OS Repo beginnt Entwicklung so: Bevor eine Zeile Code existiert, steht in brand/design-system.md:
## Farben
- Accent: #D6524C (Dirty Red)
- Background: #0E0E0E
- Surface: #1A1A1A
- Foreground: #DCDCDC
## Typografie
- Display-Font: Barlow Condensed, 700, letter-spacing 0.25em
- Body: Inter, regular
## Effekte
- Glow: text-shadow 0 0 10px rgba(214, 82, 76, 0.5)
- Chromatic Aberration: 2px 0 rgba(214,82,76,0.6), -2px 0 rgba(0,200,255,0.25)
## Prinzipien
- Industriell, nicht verspielt
- VHS-Ästhetik meets technische Präzision
# CSS
- Tailwind 4.1
- BEMJetzt schreibt ein Agent CSS. Nicht irgendwelches CSS, sondern CSS das exakt zu diesem Projekt passt, weil die Entscheidungen bereits existieren. Keine Diskussion über Farben während der Entwicklung. Keine inkonsistenten Komponenten. Der Agent implementiert, was definiert wurde.
Dasselbe gilt für Architekturentscheidungen. Für Deployment-Prozesse. Für Daten-Schemas. Für Texte und Tonalität.
Das modulare Ökosystem: OS Repo als Herzstück
Hier liegt ein Missverständnis, das ich früh auflösen will: Das OS Repo ist kein Ersatz für andere Systeme und Code-Repositories. Es ist das Herzstück, an das andere Systeme andocken, oder auch nicht.
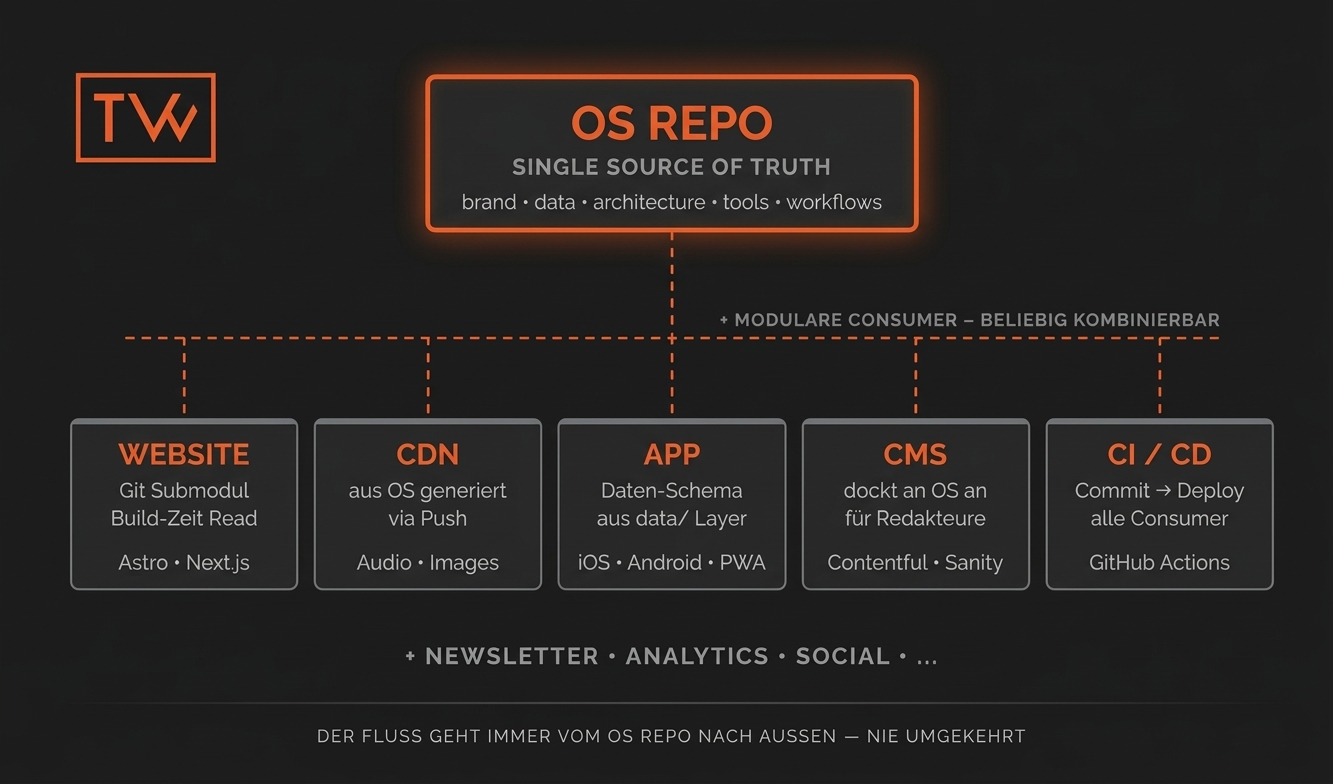
Das OS Repo generiert Content und Daten und dient als Keeper of Context. Die Consumer-Systeme nehmen, was sie brauchen. Eine API oder ein CMS kann andocken, etwa wenn Redakteure ohne Git-Kenntnisse Inhalte pflegen sollen. Ein CDN bekommt Assets, die aus dem Kontext des OS Repos generiert wurden. Die Website liest Projektdaten zur Build-Zeit. Eine Mobile App nutzt dieselbe API-Definition aus data/schema.json.
Kein System ist obligatorisch. Jedes ist modular austauschbar. Das OS Repo selbst bleibt stabil.
Das ist der entscheidende Punkt: Die Pipeline ist nicht Content-Delivery, sie ist Content-Generierung. Was auf dem CDN liegt, wurde aus dem OS Repo heraus erzeugt. Was die Website anzeigt, stammt aus data/releases.json im OS Repo. Was das CMS verwaltet, kann auf Daten aus dem OS Repo aufbauen. Der Fluss geht immer vom OS Repo nach außen, nie umgekehrt.
Daten als Teil des Repos: Der maschinenlesbare Layer
Neben der menschenlesbaren Dokumentation hat ein OS Repo einen maschinenlesbaren Daten-Layer in JSON oder YAML. Das ist der Kanal, über den Consumer-Systeme Projektdaten beziehen.
Eine releases.json für alle Veröffentlichungen eines Labels. Eine products.json für einen Shop. Eine team.json für eine Agentur. Eine services.yaml für eine SaaS-Plattform. Das Schema liegt auch im Repo, Agents und Tools wissen, welche Felder existieren und was sie bedeuten.
{
"releases": [{
"catalog": "PG-001",
"artist": "Input Null",
"title": "Vector Field Signals",
"cover": "https://cdn.example.com/releases/pg-001/artwork/cover_600.jpg",
"tracks": [
{ "number": 1, "title": "Duality Shift Exchange", "url": "..." }
]
}]
}Diese Datei ist keine Datenbank. Sie ist keine API. Sie ist eine Textdatei in Git, versioniert, diffbar, reviewbar, von Menschen schreibbar und von Maschinen lesbar. Ein Agent kann sie bearbeiten. Ein Merge-Request zeigt exakt was sich geändert hat. Das Deployment passiert durch den Commit.
GitOps und Submodule: Text als Deployment-Mechanismus
Das OS Repo hat eine natürliche Verlängerung in die Deployment-Welt: GitOps. Die Grundidee, Git ist nicht nur Versionskontrolle für Code, sondern der einzige Mechanismus über den Änderungen in die Welt kommen. Kein Dashboard. Kein manuelles Klicken. Ein Commit ist ein Deployment.
Git-Submodule sind dabei die Verbindungsschicht zwischen OS Repo und Consumer-Repos:
project-os/ ← OS Repo, Änderung committed
└── data/releases.json
project-web/ ← Consumer, bindet OS Repo ein
└── project-os/ ← Submodul, zeigt auf konkrete SHA
└── data/releases.jsonDas Web-Repo bindet das OS Repo nicht als Dependency ein, sondern als eingefrorenen Stand. Jeder Commit hat eine SHA. Das Consumer-Repo zeigt explizit auf einen bestimmten Stand. Das ist keine Einschränkung, es ist Kontrolle. Welcher Stand ist gerade live? git submodule status. Was hat sich seit letztem Deployment geändert? git diff HEAD~1 -- project-os/.
Kombiniert mit GitHub Actions entsteht eine vollautomatische Kette:
# OS Repo: bei Daten-Änderungen alle Consumer benachrichtigen
on:
push:
paths: ['data/**']
jobs:
notify:
steps:
- name: Trigger web rebuild
run: |
curl -X POST \
-H "Authorization: token ${{ secrets.DISPATCH_TOKEN }}" \
https://api.github.com/repos/org/project-web/dispatches \
-d '{"event_type":"os-updated"}'# Web Repo: auf Benachrichtigung vom OS Repo reagieren
on:
repository_dispatch:
types: [os-updated]
jobs:
deploy:
steps:
- uses: actions/checkout@v4
with:
submodules: recursive
- run: pnpm build && pnpm deployEin Commit im OS Repo triggert automatisch alle Consumer, die sich dafür registriert haben. Die Website rebuildet. Der Newsletter-Generator läuft. Die App holt neue Daten. Kein Mensch muss koordinieren.
Und für Projekte, bei denen Agents zentrale Akteure sind, ist das sicherheitsrelevant: Git ist das Review-Gate. Der Agent committed, ein Mensch reviewed per Pull Request, der Merge triggert das Deployment. Kein Agent hat direkten Zugriff auf Production-Systeme, nur auf Git.
Tools im Repo: Kein Tool ist extern
Ein OS Repo enthält die Werkzeuge, die zum Projekt gehören. Nicht als Abhängigkeiten zu externen Systemen, sondern als Teil des Repos selbst.
./pg convert <release-path> # Audio konvertieren, Artwork exportieren
./pg push <release-path> # CDN Upload + Daten-Update
./pg social <release-path> # Social Assets generierenDiese Befehle liegen als Scripts im Repo, neben der Dokumentation, die erklärt wann man sie aufruft. Der Agent der sie aufruft, kennt sie, weil sie im selben Repo sind wie der Rest des Projekts.
Das bedeutet: Ein Agent kann einen vollständigen Release-Prozess durchführen, Konvertierung, Upload, Website-Update, Commit, ohne jemals das Repo verlassen zu müssen. Alle Werkzeuge sind da. Alle Anweisungen sind da. Alle Daten sind da.
Warum jetzt? Das Timing des Paradigmenwechsels
AGENTS.md ist aus einem spezifischen Moment entstanden: dem Moment, in dem Agenten kompetent genug wurden, um eigenständig an Codebases zu arbeiten, aber noch kein Framework existierte, das ihnen dabei half.
Dieser Moment ist vorbei. Agenten können heute ganze Features selbständig implementieren, Bugs debuggen, Deployments durchführen. Das Problem ist nicht mehr Kompetenz, es ist Kontext und Konsistenz.
Wenn ein Agent bei jeder Session neu lernen muss, was zu einem Projekt gehört, welche Designentscheidungen getroffen wurden, welche Architektur gilt, welche Prozesse existieren, dann verliert man den größten Vorteil agentischer Entwicklung: Geschwindigkeit durch akkumuliertes Wissen.
Das OS Repo löst genau das. Es ist das persistente Gedächtnis eines Projekts. Es wächst mit dem Projekt. Es ist versioniert. Es ist diffbar. Es ist reviewbar.
Und es zwingt das Team, oder den Solo-Entwickler, dazu, das Projekt zu denken, bevor es baut. Das ist keine Einschränkung. Das ist der eigentliche Mehrwert.
Wie man anfängt
Ein OS Repo muss nicht vollständig sein, um nützlich zu sein. Die Einstiegsschwelle ist bewusst niedrig:
Schritt 1, Projekt definieren, nicht beschreiben. Nicht “Wir bauen eine Website”, sondern: Welche Farben? Welche Fonts? Welcher Ton? Welche Technologien und warum? Das in Markdown, im Root des Repos.
Schritt 2, Daten strukturieren. Was sind die Kerndaten des Projekts? Releases, Produkte, Team, Kunden, in JSON oder YAML definiert, mit klarem Schema.
Schritt 3, Workflows dokumentieren. Wie läuft ein Release ab? Wie deployed man? Wie entsteht ein neues Feature? Schritt für Schritt, in natürlicher Sprache.
Schritt 4, Tools einbinden. Wiederkehrende Prozesse als Scripts, direkt im Repo. Ein ./project <command> als einheitliches Interface.
Schritt 5, Consumer-Repos anschließen. Website, App, Infrastruktur, als separate Repos, die das OS Repo per Git-Submodul einbinden. Daten fließen aus dem OS Repo in die Consumer. Nicht umgekehrt.
Das ist kein Overhead. Es ist Arbeit, die sowieso anfällt, nur jetzt bewusst, strukturiert, an einem Ort, für Menschen und Maschinen lesbar.
Was AGENTS.md wird, wenn man es konsequent denkt
Die Community diskutiert gerade einen .agent/-Verzeichnis-Ansatz als Erweiterung zu AGENTS.md. Mehr Struktur, mehr Tiefe, mehr Kontext. Das ist der richtige Instinkt.
Das OS-Repo-Prinzip ist, was dabei herauskommt, wenn man diesen Gedanken zu Ende führt: Kein einzelnes Verzeichnis, kein einzelnes Repo-Anhängsel, sondern ein eigenständiges Repo, das das Projekt ist, bevor es gebaut wird.
AGENTS.md beschreibt, wie man in einem Codebase arbeitet.
Ein OS Repo beschreibt, was ein Projekt ist.
Das ist der Unterschied.
Phantom Grid, ein Elektronik-Label, das ich gerade aufbaue, ist das Projekt, an dem ich das OS-Repo-Prinzip in der Praxis entwickle. Der gesamte Stack, Design System, Release-Workflow, CDN-Upload, Website, wird aus einem einzigen Repo gesteuert. Der Code ist auf GitHub: github.com/Tobeworks/phantom-grid-os
Kommentare